


行業新聞
忘記可能是AI進步的關鍵
日期:2019-06-26
來源:J9九游会中国
盡管忘記有時候會使我們感到沮喪,但人類忘記的能力正是我們優於人工智能的地方。計算機記憶即電腦內存,通常是指存儲信息和找回信息的容量,以及存儲這些信息的計算機物理組件。當計算機的某些內存不再被任務需要時,計算機將“忘記”這些數據,釋放空間供其他任務源。
AI存儲記憶的一種方法是象征性的記憶表征,其中,知識是由邏輯事實來表示的(如“鳥會飛”,“Tweety是鳥”,因此“Tweety可以飛”)。這些高度結構化的人造表示雖然可以很容易地刪除,就像在電腦上刪除一個文件。但是機器學習算法不知道需要什麽時候保留舊信息,什麽時候拋棄過時的信息。不僅如此,它還會麵臨著與“遺忘”有關的幾個問題。
一個是“過學習”的問題。“過學習”指的是當一個學習機器存儲了源於以往經驗的過於詳細的信息時,阻礙了其概括和預測未來事件的能力。另外有時人造神經網絡的神經元在學習過程的早期采用不良的激活模式,會損害AI的未來學習能力。
還有一個問題是“災難性遺忘”。 比如如果教一個說英語的孩子學習西班牙語,孩子會很容易把學習英語的方法應用到西班牙語的學習中,比如名詞,動詞時態,句子構建,同時忘記那些不相關,比如口音,喃喃自語,語調。人類可以同時進行遺忘和學習。
相反,如果訓練神經網絡學習英語,則參數需要適用於英語。如果還想同時教它西班牙語,對西班牙語的新改編將覆蓋神經網絡以前為英語獲得的知識,有效地刪除所有內容並重新開始。這被稱為“ 災難遺忘 ”,也是神經網絡的一個局限。
倫理方麵的考量也是一個問題。人類死後他們的數據要怎麽處理?一旦那個人死了,是否能夠用這些數據再訓練AI然後複製出另一個他?缺乏適用的法律、規則,沒有設定好的邊界,我們留下了一個沒有人控製的分散係統。算法不能選擇忘記什麽,而負責它們的人可能沒有權利或解決問題的能力。
廉價的信息存儲代價和AI無窮的容量相結合,打造出了一個看似非常有吸引力的工具,但背後的問題是大量數據持續的收集,而沒有簡單的方法來“忘記”數據。
教會AI遺忘,要創造更好的人工智能,首先要了解我們的大腦在關於什麽是值得記住的,什麽是要遺忘的方麵是如何做決定的。
然後應用到AI,就像人一樣,人工智能應該記住重要和有用的信息,同時忘記低價值,無關緊要的知識。然而,確定什麽是相關和有價值的信息,除了手頭的任務之外,還加入包括如倫理,法律和隱私問題等因素。
學會遺忘是人工智能麵臨的重大挑戰之一。雖然它仍然是一個新的領域,但科學家最近已經探索了一些關於如何克服這一局限的常識性理論,比如循環神經網絡LSTM,它使用特定的學習機製來決定要記住哪些信息,要更新哪些信息,以及在任何時候注意。
還有穀歌DeepMind的研究人員提出的EWC算法,該算法模仿突觸合並的神經運作過程。在神經網絡中,使用多個連接(如神經元)來執行任務。EWC將某些連接編碼為關鍵,從而保護它們不被覆蓋/遺忘。
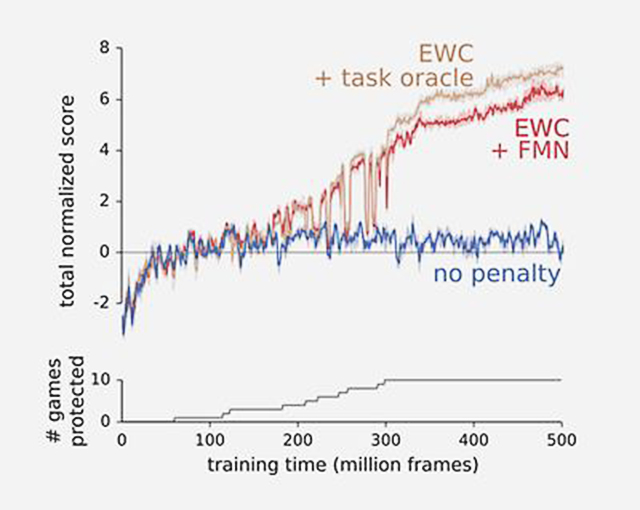
藍線=標準深度學習,紅色和棕色線=在EWC的幫助下進行改進
但是未來真正的轉變還需要領導人工智能開發,技術專家,倫理學家,研究人員,學者,社會學家,政策製定者和政府的私人實體的共同合作。
