


行業新聞
關於自動機器學習的概述
日期:2019-08-15
來源:J9九游会中国
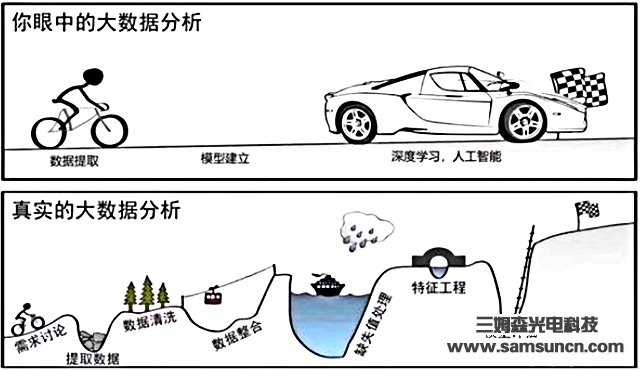
機器學習是讓算法自動的從數據中找出一組規則,從而提取數據中對分類/聚類/決策有幫助的特征,隨著機器學習的發展,其中人工需要幹預的部分越來越多,而自動機器學習則是對機器學習模型從構建到應用的全過程自動化,最終得出端對端的模型(end to end)。有了自動機器學習,機器學習就會從下圖的曲折變為上圖的一馬平川。
從流程先後順序來分,最初是數據準備,包括數據收集和清洗,之後是特征工程,其中包括特征選擇(決定哪些特征需要保留),特征提取(對特征進行降維,常用的方法例如PCA),特征組合(將多個特征合並/構建為一個新的特征)。
在之後的模型構建中,最關鍵的是模型選擇,之後超參數優化,可以采取很多方式,最簡單的做法是網格搜索,常用的方法包括用強化學習,進化算法,貝葉斯優化,以及梯度下降,來縮小搜索空間;最後,AutoML通過引入提前停止,降低模型的精度,參數共享來自動化模型評價的過程。
數據收集這項任務,不在是搜索與收集真實數據,還包括產生模擬數據,用來擴展訓練數據集,可以使用的新技術包括對抗神經網絡,還可以使用強化學習的框架,來優化用於控製生成數據的參數,從而使得生成的數據能更有效的助力模型的訓練。而數據清洗則是自動完成包括缺失值補全,離群點處理,特征歸一化,類別型特征的不同編碼等之前手動完成的工作。
模型的自動化選擇,傳統的方法是從傳統的模型,例如KNN,SVM,決策樹中選出一個,或多個組合起來效果最好的模型,而當前自動機器學習的研究熱點是N eural Architecture Search, 也就是不經過人工幹預,模型自動生成一個對當前任務最有效的網絡結構,模型自動在自我生產的不同結構下搜索最好的操作組合序列。
這裏的行為是以一定的概率選擇某個網絡結構,行為是在該結構下,訓練子網絡,使其在訓練集上達到預設的準確率,獎勵是該子網絡在測試數據集上的準確率與該網絡被選擇的概率的乘積,通過將子模型的泛化能力作為反饋,用於控製不同模型被選擇概率的RNN得以優化其梯度,以選出泛化能力最強的模型,同時通過始終保持一定概率選擇其他模型,處理explore VS exploit的權衡。
NAS算法作為當前自動機器學習最熱的研究領域,有很多變種,不同NAS方法的效果及訓練用時。相比於強化學習和進化算法,傳統方法的用時更少。為了找到合適的網絡架構,除了傳統的串行網絡,還有基於cell來做層級化網絡架構搜索的。先從幾個最基本的操作,搜索得出一個一級的網絡組件,之後在自動化的搜索如何用一級組件搭建網絡。
模型選定後的調參過程,最常用的是網格搜索,也就是按照固定的間距,在搜索空間上打點,但下圖指出,網格搜索不一定好過隨機搜索,原因是對於重要參數,網格搜索采樣地點會不足,從而導致無法取到對模型效果相對較好的點,autoML會使用隨機抽樣,首先評價各個超參數的重要性,之後再對重要的參數進行微調。
從流程先後順序來分,最初是數據準備,包括數據收集和清洗,之後是特征工程,其中包括特征選擇(決定哪些特征需要保留),特征提取(對特征進行降維,常用的方法例如PCA),特征組合(將多個特征合並/構建為一個新的特征)。
數據收集這項任務,不在是搜索與收集真實數據,還包括產生模擬數據,用來擴展訓練數據集,可以使用的新技術包括對抗神經網絡,還可以使用強化學習的框架,來優化用於控製生成數據的參數,從而使得生成的數據能更有效的助力模型的訓練。而數據清洗則是自動完成包括缺失值補全,離群點處理,特征歸一化,類別型特征的不同編碼等之前手動完成的工作。
模型的自動化選擇,傳統的方法是從傳統的模型,例如KNN,SVM,決策樹中選出一個,或多個組合起來效果最好的模型,而當前自動機器學習的研究熱點是N eural Architecture Search, 也就是不經過人工幹預,模型自動生成一個對當前任務最有效的網絡結構,模型自動在自我生產的不同結構下搜索最好的操作組合序列。
這裏的行為是以一定的概率選擇某個網絡結構,行為是在該結構下,訓練子網絡,使其在訓練集上達到預設的準確率,獎勵是該子網絡在測試數據集上的準確率與該網絡被選擇的概率的乘積,通過將子模型的泛化能力作為反饋,用於控製不同模型被選擇概率的RNN得以優化其梯度,以選出泛化能力最強的模型,同時通過始終保持一定概率選擇其他模型,處理explore VS exploit的權衡。
NAS算法作為當前自動機器學習最熱的研究領域,有很多變種,不同NAS方法的效果及訓練用時。相比於強化學習和進化算法,傳統方法的用時更少。為了找到合適的網絡架構,除了傳統的串行網絡,還有基於cell來做層級化網絡架構搜索的。先從幾個最基本的操作,搜索得出一個一級的網絡組件,之後在自動化的搜索如何用一級組件搭建網絡。
模型選定後的調參過程,最常用的是網格搜索,也就是按照固定的間距,在搜索空間上打點,但下圖指出,網格搜索不一定好過隨機搜索,原因是對於重要參數,網格搜索采樣地點會不足,從而導致無法取到對模型效果相對較好的點,autoML會使用隨機抽樣,首先評價各個超參數的重要性,之後再對重要的參數進行微調。
